【问小白导读】:Deep Research作为一类被广泛使用的AI智能体,一直缺乏统一的评估标准来量化他们的能力。今天问小白技术团队为大家带来Deep Research Bench,一个全新的评估基准用于全面评估Deep Research类智能体。
1. 论文背景
2025年初,OpenAI率先发布了他们的Deep Research -- 一个全新的深度调研智能体(AI Agent),效果很快惊艳了国内外网友。很快,一众竞争对手闻风而动,包括Google、Grok、Perplexity以及国内大厂都迅速跟上,竞相发布了自家的相关Agent产品。这是继以Cursor为代表的编码类AI Agent之后又一类AI Agent脱颖而出,受到了用户的广泛认可。
既然有了这么多的Deep Research,那大家自然会产生疑问:
谁才是最厉害的Deep Research?不同的Deep Research又分别擅长哪一类任务?
为了解答这个疑惑,问小白技术团队联合中国科学技术大学提出了Deep Research Bench--一个全新的评估基准,用来全面地衡量不同Deep Research的能力。这个评估基准为用户和社区提供了一个直观的窗口,通过它可以观察各家调研类AI Agent的能力差异和发展情况。

https://arxiv.org/pdf/2506.11763
💻 代码仓库:
https://github.com/Ayanami0730/deep_research_bench
🌐 论文主页:
https://deepresearch-bench.github.io
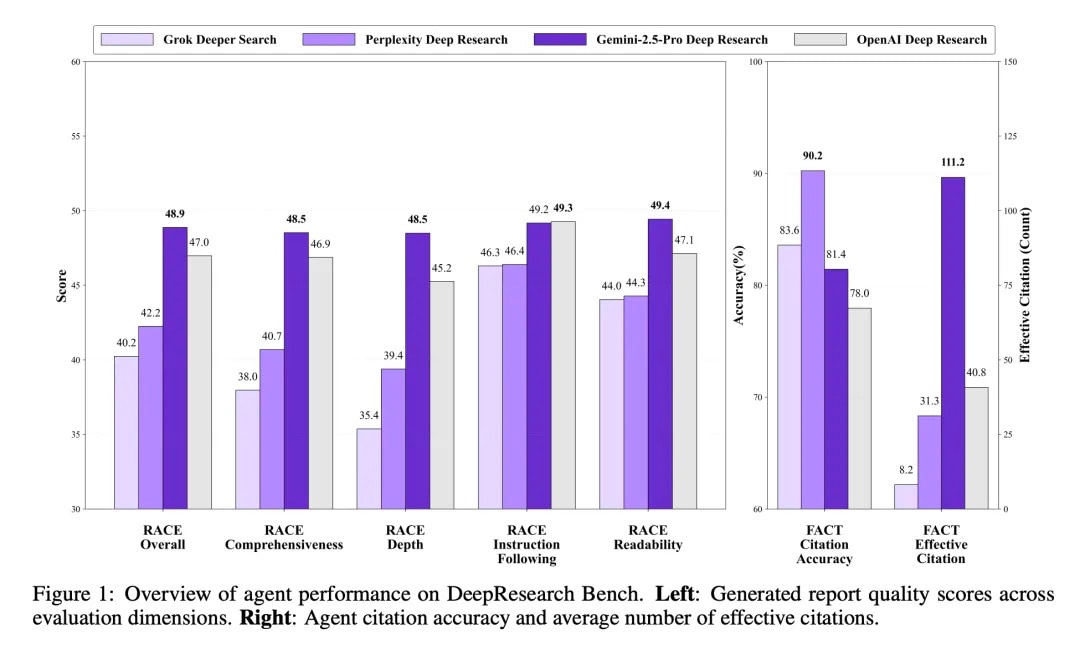
如图二,可以清晰地看到四个主流的Deep Research智能体(Grok Deeper Search、Perplexity Deep Research、Gemini-2.5-Pro Deep Research和OpenAI Deep Research)在我们评估基准上的表现。其中左图中的RACE是指代我们的文章质量评估框架(后文会介绍),Overall就是总体表现,往后依次为全面性、深入性、指令遵循能力以及可读性。右图是FACT框架评估的结果,主要包含了引用准确率和有效引用数这两个评估维度。可以看到基于Gemini-2.5-Pro的Deep Research目前总体表现最佳。
2. 基准构建
DeepResearch Bench评估基准包含了100个由专家精心设计的深度调研任务(Deep Research Task),基于这些调研任务我们设计了两种对应评估方法:RACE和FACT,他们分别用于评估Deep Research生成的文章质量以及他们检索信息、引用信息的能力。下面我们将详细介绍这个评估基准的构建过程:
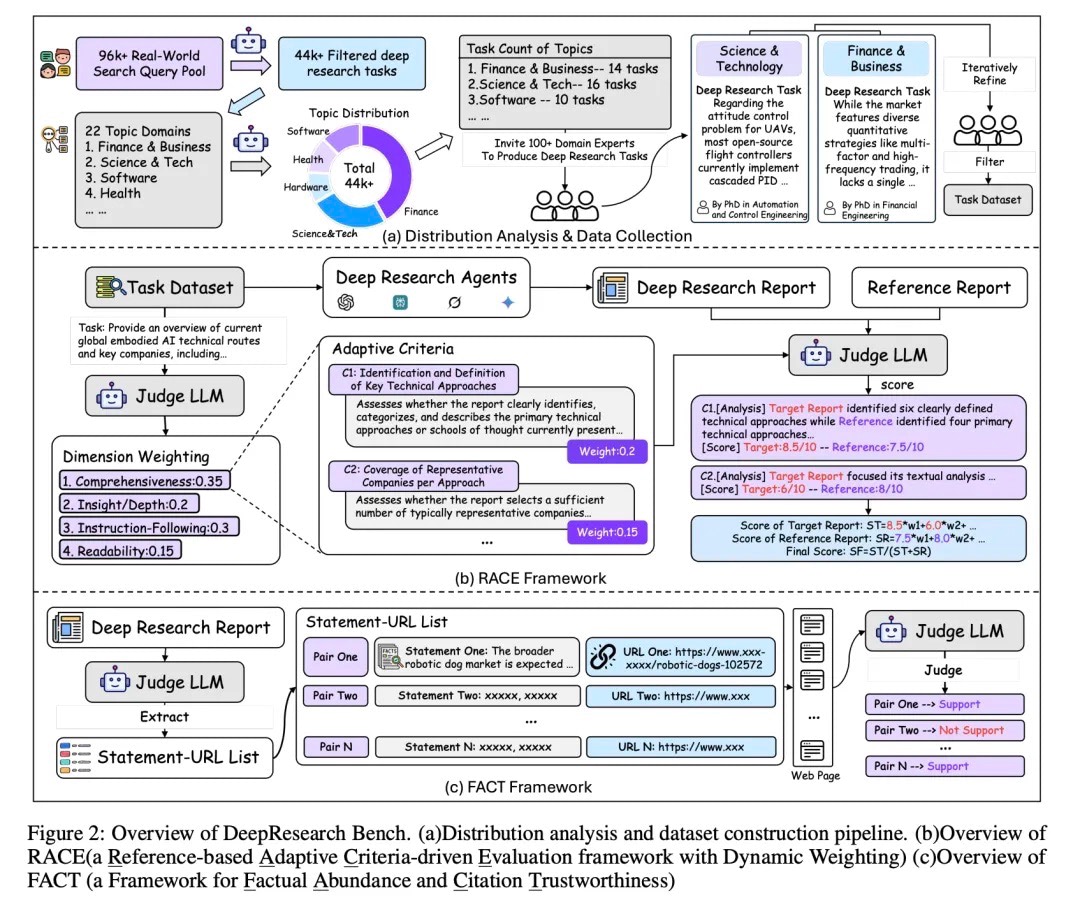
首先在构造数据集之前,我们进行前置实验分析。我们坚信构建评估基准必须基于真实的用户需求,这样才能真实反映Deep Research到底多大程度地完成了用户设定的目标。我们对一个包含约100k条相关问题的内部数据集进行模糊处理,进行数据脱敏,随后通过过滤、分类等步骤最终获得了用户对Deep Research真实需求的主题分布(Topic Distribution)。
基于这个分布我们确定了测试数据中每个主题应该包含的任务数量,并邀请了相关领域的博士级别的专家来编写调研任务,最终构造了这个测试数据集。
RACE(Reference-based Adaptive Criteria-driven Evaluation framework with Dynamic Weighting):基于参考的自适应标准驱动评估框架(具有动态权重)。
FACT(framework for Factual Abundance and Citation Trustworthiness):事实充分性与引用可信度评估框架。
前者通过构造动态评判标准(criteria)和权重(weight)的方法来评估文章的最终质量,并引入参考文章(reference)以提升评估的稳定性。
后者通过抽取Deep Research文章中的"引用-链接"对,抓取链接对应的网页内容,然后逐个检验模型的引用是否准确。通过这两种方法,我们提供了一个全面、鲁棒、可扩展(Scalable)且高度人类对齐的自动化评估框架。
3. 评估结果
现在我们来看一下使用我们DeepResearch Bench评估不同Deep Research的结果。
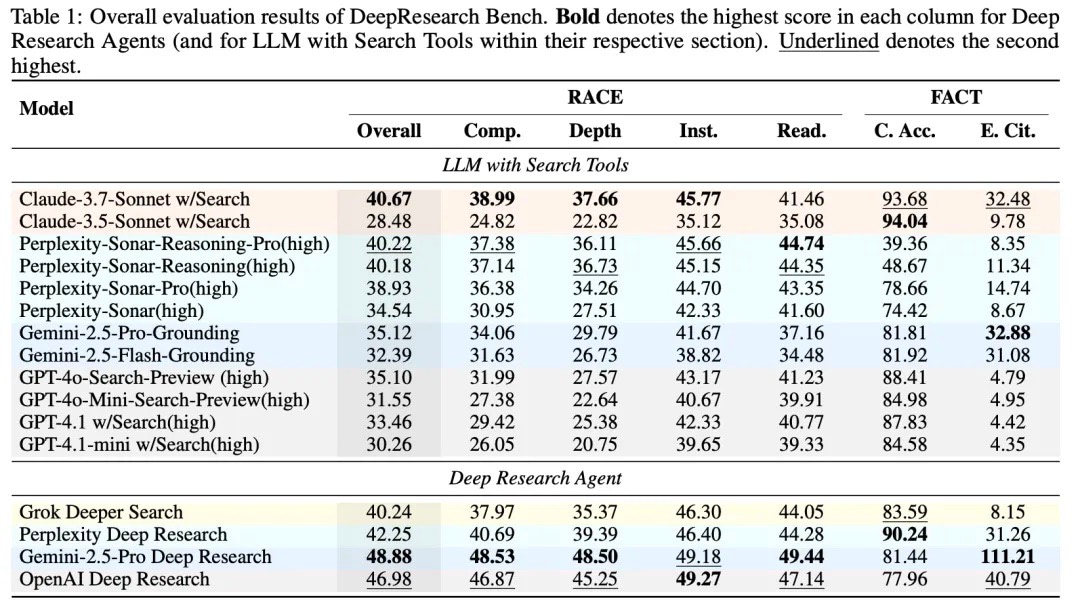
专门为深度研究定制的AI Agent表现突出,其中Gemini-2.5-Pro Deep Research在RACE框架的整体评估中表现最佳,得分48.88分;OpenAI Deep Research紧随其后,得分46.98分。值得一提的是,后者在指令遵循维度甚至超越了Gemini。
我们还进一步将Deep Research与各家SOTA模型+搜索工具进行比较,在这些带搜索工具的模型中,Claude-3.7-Sonnet表现令人印象深刻,整体得分40.67分,甚至超过了专门的深度研究智能体Grok Deeper Search。Claude的调研报告写作能力一向令人印象深刻,但获得如此高分同时也可能得益于Claude的API允许模型进行多轮网络搜索,获取了更丰富的信息。
FACT框架的评分结果充分体现了"引用数量vs准确性的权衡"。Gemini-2.5-Pro Deep Research在有效引用数量上遥遥领先,平均每篇文章达到了超过111个有效引用,远超其他模型,这与其在"全面性"维度的高分相呼应。但在引用准确性方面,Gemini的表现则相对较差,而Perplexity Deep Research则表现更优,显示出更强的内容回忆和引用精准度。
4. 人类一致性
为了验证我们评估方法的有效性,我们使用4个Deep Research产品(OpenAI、Gemini、Perplexity和Grok)以及数据集中的中文任务来进行人类一致性实验。每个任务邀请了3个志愿者(相关专业在读硕博)对四个模型进行打分,并最后与我们的文章质量评估方法RACE来计算一致性。
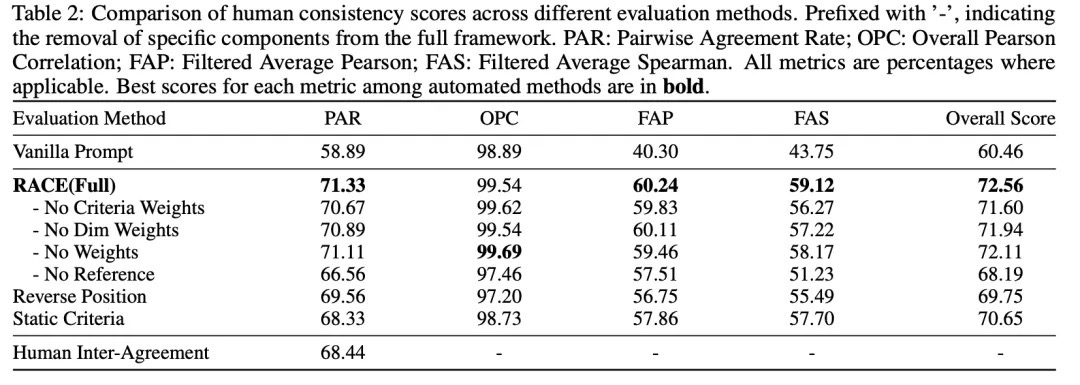
人类一致性实验总计招募志愿者进行了225个人小时的评分工作,并最终验证我们RACE完整方法的人类一致性大幅超越基线的LLM-as-a-Judge方法,也优于自身任何变体。
我们的评估方法成对一致性达到71.33%优于人类专家间的一致性68.44%,总分Pearson一致性达到了99.54%。说明我们的评估方法给不同Deep Research打出的总体评分与人类专家的评分线性相关程度极高。
5. 结语
最后,论文中的所有数据以及评估框架的代码已经全部开源,可以参考文章开头的链接,如有任何问题欢迎联系问小白团队进行交流。问小白技术团队将继续深耕AI Agent和Deep Research 方向,为社区贡献更多有意义的工作。
我们也将持续维护Deep Research Bench的评估生态,扩大测试集的规模同时开发更鲁棒更准确的评估方法,希望能帮助用户清晰的判断不同AI Agent的能力差异,更好的拥抱AI产品。